I have compiled some useful features of three desktop environments into one desktop environment. The global menu which is effectively applied in the MacOS, the idea of left dock of Ubuntu, the lightweight-ness of XFCE, and the productive-ness of Xmonad, one of the tiling window managers.
I made a script that automatically turns Ubuntu based Xfce desktop to my configuration. I recommend trying this on a Linux Lite installation. Alternatively, you could try installing it on an Ubuntu box with Xfce installed, or on Xubuntu. Feedbacks are all welcome about other distributions.
Xmonad is configured using xmonad.hs in ~/.xmonad. According to the configuration, the mod key is set as Win/Cmd key.
The keyboard shortcuts are as follows:
The ordering of the tiling setups are as follows:
xmonad, xfce4-dockbarx-plugin, gnome-terminal, zeitgeist, python-xdg, vala-panel-appmenu, appmenu-gtk3-module, appmenu-gtk2-module, appmenu-qt, gnome-terminal, xmonad, shutter, xfce4-appmenu-plugin, xfce4-systemload-plugin, arc-theme
Please note that, the script will install google-chrome amd64 binary. If you have other hardware, you should modify the related line. The script will install Arc Dark theme and switch to it.
After running the script, you will have a desktop environment that looks like the following screenshots:
| Shortcut | Task |
| Shift + Mod + c | Close the active window |
| Shift + Mod + s | Take xfce4-screenshot |
| Shift + Mod + x | Reverse tiling windows according to x-axis |
| Shift + Mod + y | Reverse tiling windows according to y-axis |
| Shift + Mod + h | Increase the width of left pane |
| Shift + Mod + l | Increase the width of right pane |
| Mod + Up | Increase the height of windows in the right pane |
| Mod + Down | Decrease the width of windows in the right pane |
| Mod + Space | Switch to another tiling setup |
| Mod + Tab | Switch to next window in the workspace |
| Mod + z | Switch to the previous workspace |
| Mod + (1|2|3|4|5|6|7|8|9) | Switch to the workspace indicated by the number |
| Shift + Mod + (1|2|3|4|5|6|7|8|9) | Move the active window to the workspace indicated by the number |
The ordering of the tiling setups are as follows:
- Master window on left, others on right
- Master window on top, others at bottom
- Only master window in full screen with left and top panels
- Only master window in full screen (useful for watching full screen video)
xmonad, xfce4-dockbarx-plugin, gnome-terminal, zeitgeist, python-xdg, vala-panel-appmenu, appmenu-gtk3-module, appmenu-gtk2-module, appmenu-qt, gnome-terminal, xmonad, shutter, xfce4-appmenu-plugin, xfce4-systemload-plugin, arc-theme
Please note that, the script will install google-chrome amd64 binary. If you have other hardware, you should modify the related line. The script will install Arc Dark theme and switch to it.
After running the script, you will have a desktop environment that looks like the following screenshots:
You can preview media easily utilizing the tiling window manager:
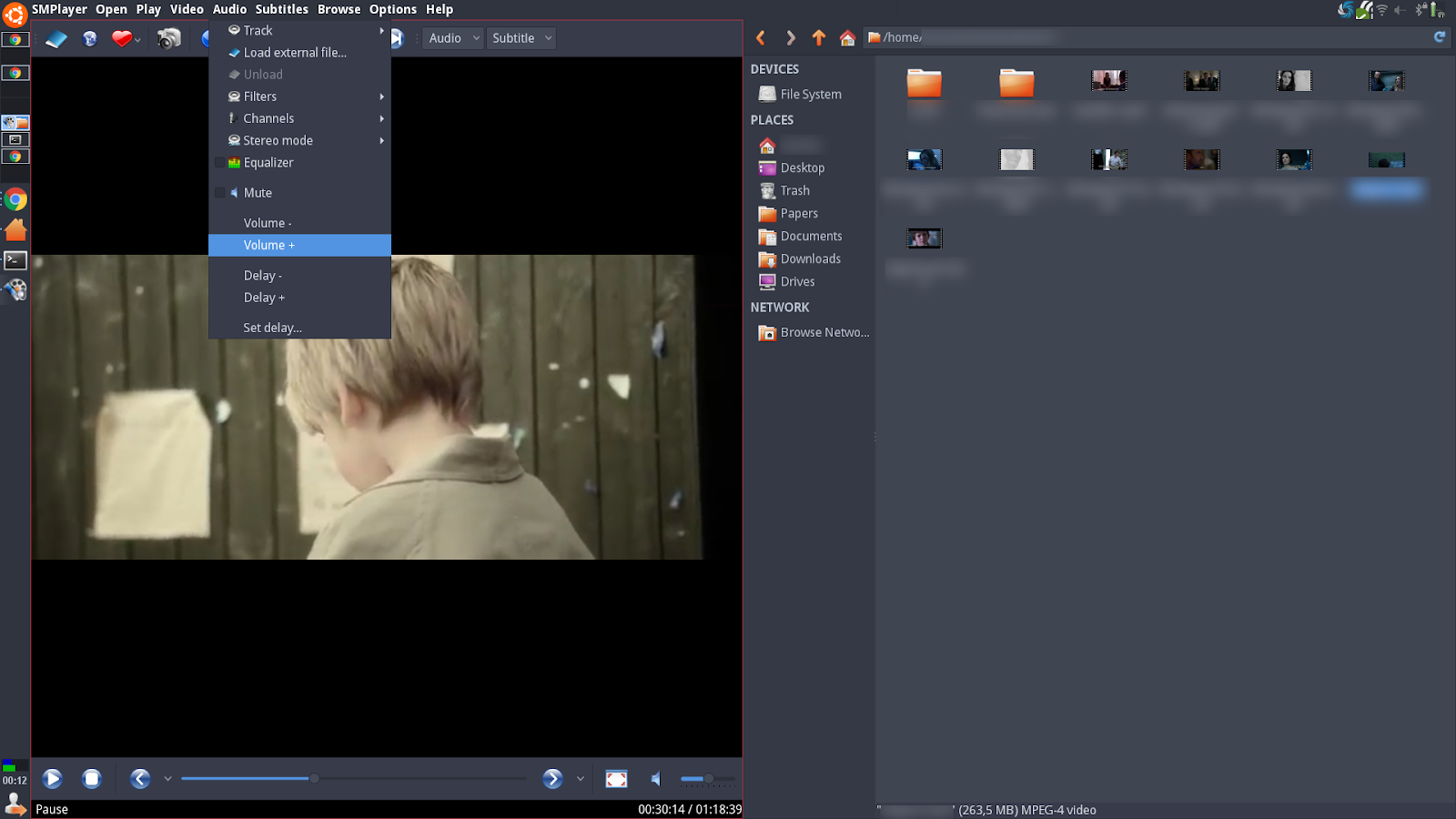
You can prepare your own IDE like environment. For example, the picture shows preview of a pdf paper at the right side, and tex file editor at the left. At the bottom of the left side, a command line is present to compile the tex file into pdf. The pdf viewer at the right side immediately previews if a new compilation occurs. 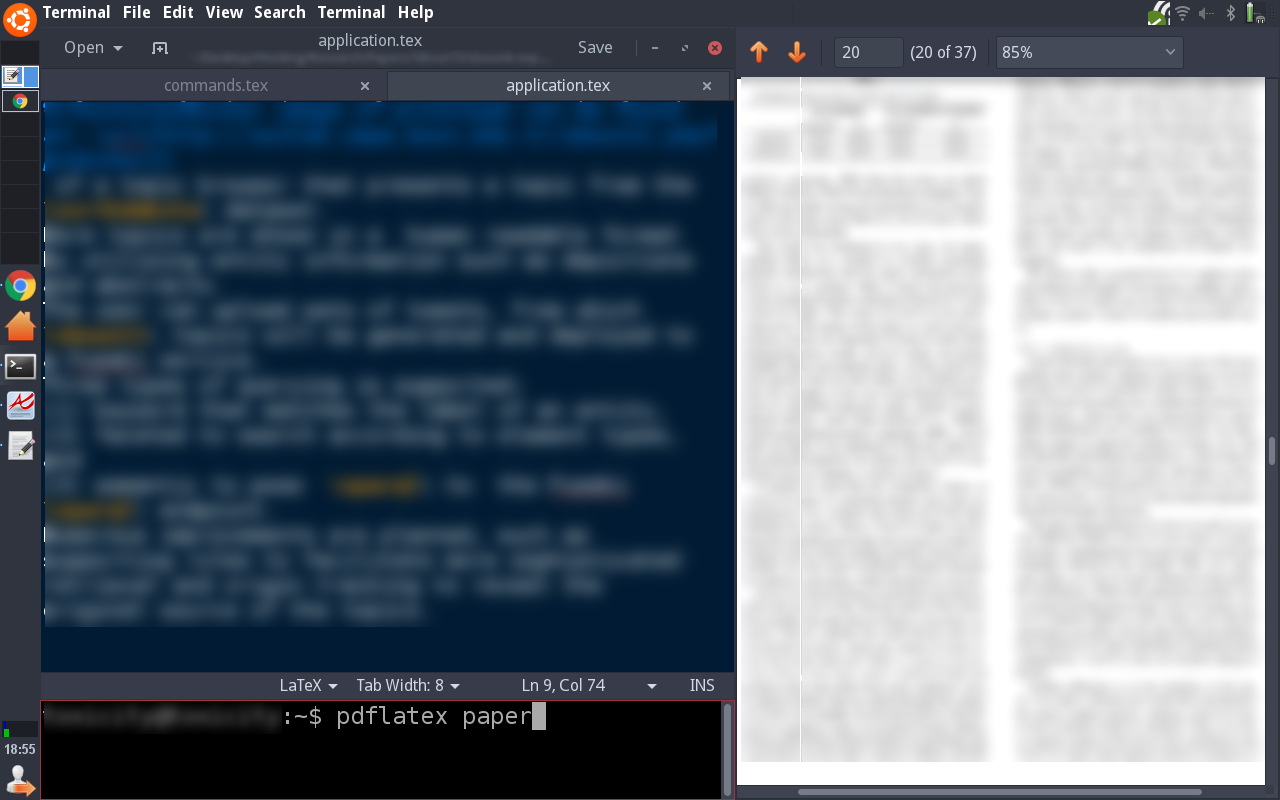
The following pictures show Chrome in full screen. The first picture demonstrates the top global menu. The second picture demonstrates the left dock.